Structured Data from Unstructured Conversations:Reliable Data Extraction Best Practices
Building AI agents that interact with real systems—payments, databases, workflows, or APIs—often looks
straightforward in examples. You define a tool (or FunctionTool in the Google Agent SDK),
specify a schema,
and expect the language model to populate parameters correctly. In practice, this assumption breaks down
quickly.
While working with the Google Agent SDK and building AI agents powered by Google Gemini, I repeatedly
encountered a core reliability challenge: LLM-generated tool inputs are inherently unpredictable. Even when
parameters are explicitly defined as simple types like String, the model may supply
semantically
equivalent—but structurally different—representations such as maps, lists,
or
numbers. This behavior is not
a bug; it is a natural consequence of how large language models reason over conversational context rather
than strict schemas.
This article distills practical lessons learned from building and hardening agent workflows in real
scenarios. It focuses on best practices for extracting structured data from unstructured
conversational
input, specifically at the boundary where LLMs invoke tools. Although the examples reference
the Google
Agent SDK and Gemini, the principles apply broadly to any agent framework that relies on function calling,
tool execution, or model-driven orchestration.
The Core Challenge: Unpredictable LLM Output at the Tool Boundary
When an LLM invokes one of your defined tools, it populates the tool’s parameters based on its
interpretation of the conversation—not on strict type enforcement. Consider a simple scenario where
multiple
users attempt to perform the same action, such as making a payment. Each user may provide the required
information in a different way, across multiple turns, using varying levels of structure and precision.
As a result:
- A parameter expected to be a
Stringmay arrive as aMap,List, orNumber - A numeric value may be embedded in a list or nested object
- Previously provided information may be reformulated or partially repeated
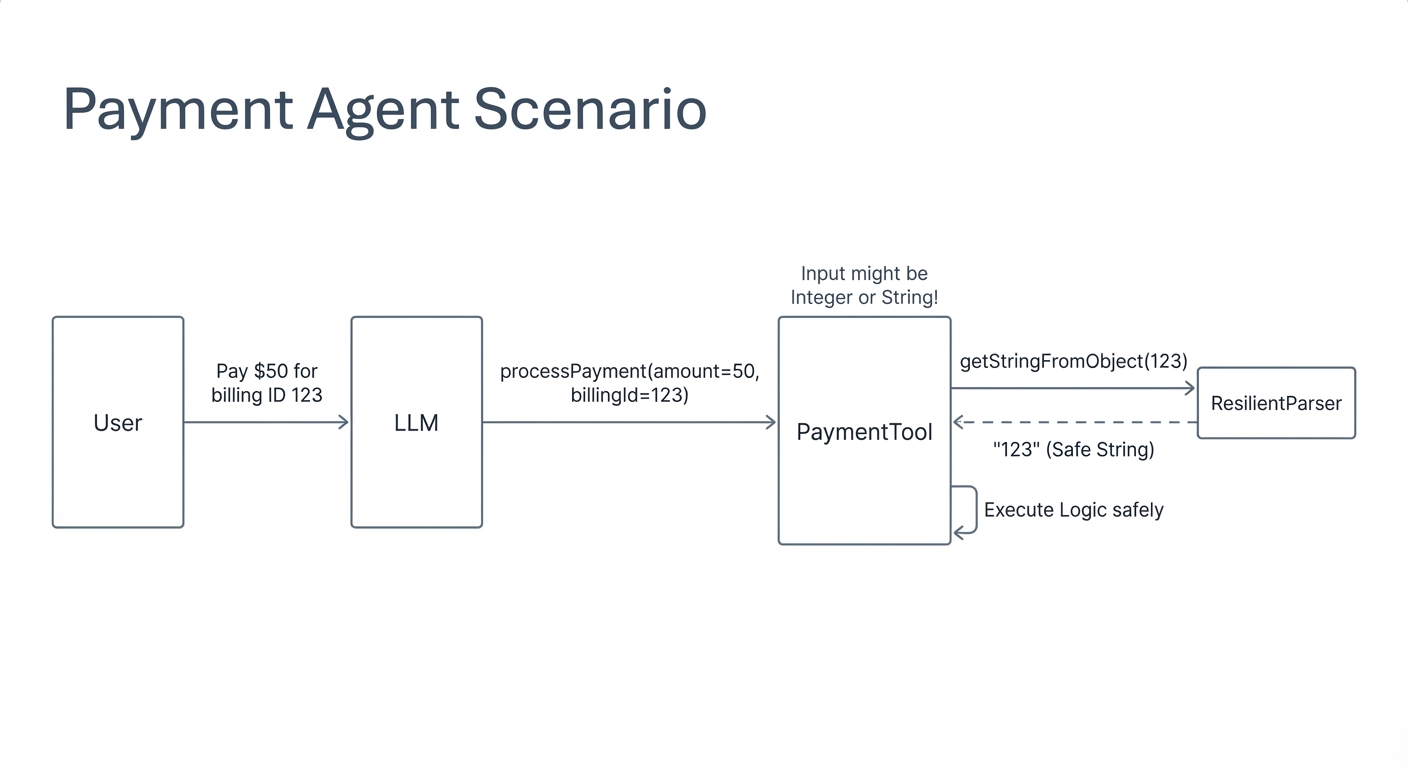
Example Scenario: A Payment Processing Agent
To make this concrete, consider an agent designed to process payments. The agent exposes two primary
tools:
processAuthorization and processPayment. These tools require structured inputs
such as a billing ID, credit card details, and an amount. The agent is responsible for gathering this
information from the user over several conversational turns before invoking the appropriate tools.
In practice, even when these inputs are specified as strings in the tool definition, the model may
supply
them in unexpected forms. A defensive utility method—such as getStringFromObject—can inspect the runtime
type of each parameter and extract a usable value regardless of whether the input arrives as a string,
map,
list, or number.
This pattern allows tools to remain robust in the face of conversational variability, ensuring that
minor
deviations in model output do not cause execution failures. The key insight is simple but critical:
tool schemas guide the model, but they do not constrain it.
Best Practices for Reliable Data Extraction in AI Agent Tools
1. Treat Tool Inputs as Untrusted and Implement Resilient Parameter Handling
LLM-generated tool inputs should be treated the same way you would treat inputs from an external API or
an
untrusted client. Even when a tool’s schema specifies a parameter as a String, the model
may
supply a Map,
List, Number, or nested structure that semantically represents the same
value.
To prevent tool execution failures, implement a defensive extraction layer that safely normalizes
incoming
parameters before use. A common approach is to centralize this logic in a utility method (for example,
getStringFromObject(Optional<Object> obj)) that inspects the runtime type and
extracts a
usable
string representation accordingly.
The key to building a robust agent is to create a utility function that can safely extract parameter
values
regardless of the input type. Instead of assuming a String, your code should be prepared to
handle
different data structures that the LLM might send.Tool parameters should be treated like API input
parameters. safely extract parameter values from the input.
This pattern ensures:
- Tool logic does not fail due to unexpected parameter shapes
- Minor schema deviations do not crash the agent
- Input normalization is consistent across all tools
Tool parameters should never be assumed to be type-safe , regardless of how strictly they are defined in the tool specification.
2. Use Tool Responses as Corrective Prompts with Specific, Actionable Feedback
Tool responses are not just error messages—they are part of the agent’s prompt loop. When a tool
invocation
fails due to missing or malformed parameters, vague responses such as “Invalid input” provide little
value
and often cause the LLM to repeat the same mistake.
Instead, tool responses should clearly specify:
- Which parameter is missing or invalid or malformed
- What format is expected
- Any constraints or validation rules that apply
- What corrective action the model should take
billingId. Please provide a valid
billing
ID
as a string.
This transforms the tool into a corrective signal, increasing the likelihood that the LLM will generate a valid follow-up call rather than entering a retry loop.
3. Instruct the Agent to Review Conversation History Before Re-Prompting the User
A common failure mode in conversational agents is repeatedly asking users for information they have already provided. This degrades user experience and signals poor agent memory. To mitigate this, tools should explicitly instruct the LLM to review prior conversation context before requesting additional input from the user. This guidance can be embedded directly in the tool response, for example:
4. Persist Critical Information Using Session State or External Storage
Conversation history alone is an unreliable source of truth for critical or frequently reused
information.
For data that must persist across multiple turns—such as billingId, user identifiers, email
addresses, or
authorization tokens—use session state or a backing data store.
Once a user provides stable information:
- Persiste immediateately in session state or external storage
- Use it in subsequent tool calls
- Avoid re-asking the user unless the value is explicitly missing or invalid
A useful mental model is: Conversation history is for reasoning; session state is for truth.
This separation significantly improves reliability, especially in long-running or multi-step agent workflows.
5. Explicitly Define Tool-Chaining and Execution Order in Prompts
In multi-step workflows where the output of one tool feeds into another, the chaining logic must be made
explicit. LLMs optimize for goal completion and may skip intermediate steps if the execution order is
ambiguous.
To avoid this:
- Clearly describe the required tool sequence in the system or developer prompt
- Specify dependencies between tool outputs and subsequent inputs
- Avoid assuming the model will infer execution order implicitly
6. Explicitly Set Model Temperature to Improve Tool Call Determinism
Model temperature has a direct impact on the consistency and predictability of tool calls. Leaving
temperature unspecified—or relying on defaults—can lead to increased variability in parameter structure
and
tool invocation behavior.
To improve reliability:
- Use lower temperatures (e.g., 0.0–0.3) for tasks requiring precise data extraction and structured output
- Use higher temperatures (e.g., 0.7–1.0) only when creativity or diverse responses are prioritized
- Document the temperature setting in the system prompt to make the behavior explicit
7. Prompt Injection
Testing for Prompt Injection is now a core best practice whenever you build AI agents or tools that consume
user input. Here’s a precise breakdown of why it’s necessary from a security, reliability, and compliance
standpoint:
Prompt injection is a security vulnerability that occurs when an attacker manipulates an AI agent
by injecting
malicious instructions into the input data. This can lead to the agent performing unintended actions, such
as
disclosing sensitive information, executing unauthorized commands, or bypassing security controls.
To prevent prompt injection attacks, you should implement the following security measures:
- Protects Against Malicious Manipulation of AI Behavior: Users can craft inputs designed to override instructions or constraints your AI agent follows. Testing ensures the agent resists unintended instruction execution, keeping enterprise data secure.
- Preserves Principle of Least Privilege: AI agents often operate with delegated or scoped permissions (OBO tokens, API scopes).Testing confirms that the AI cannot escalate privileges, enforcing security boundaries.
- Maintains Trust in AI Decision-Making:Even small prompt manipulations can produce incorrect or unsafe outputs.
- Reduces Risk of Data Leakage: Prompt injection attacks can attempt to extract user or system secrets.
- Supports Robust Error Handling & Failure Scenarios:Ensures AI does not crash, hang, or behave unpredictably, which is essential for production-scale deployments.
Prompt injection is a complex topic, and it is important to implement multiple layers of security to protect your AI agents from attacks.
Sample Code for Data Extraction
Below is a complete example of aPaymentAgent class that demonstrates this resilient approach.
The most
important method to study is getStringFromObject, which is designed to safely parse the
(Optional<Object> obj)
parameters provided by the Agent SDK.
package com.example.agents;
import com.google.adk.tools.FunctionTool;
import com.google.adk.tools.Tool;
import com.google.cloud.vertexai.api.FunctionDeclaration;
import com.google.cloud.vertexai.api.Schema;
import com.google.cloud.vertexai.api.Type;
import java.util.List;
import java.util.Map;
import java.util.Optional;
public class PaymentAgent {
public List<Tool> getTools() {
return List.of(
new FunctionTool(getProcessAuthorizationFunction()),
new FunctionTool(getProcessPaymentFunction())
);
}
private FunctionDeclaration getProcessAuthorizationFunction() {
return FunctionDeclaration.newBuilder()
.setName("processAuthorization")
.setDescription("Authorizes a payment method for a given billing ID.")
.setParameters(Schema.newBuilder()
.setType(Type.OBJECT)
.putProperties("billingId", Schema.newBuilder().setType(Type.STRING).setDescription("The billing ID to authorize.").build())
.addRequired("billingId")
.build())
.build();
}
private FunctionDeclaration getProcessPaymentFunction() {
return FunctionDeclaration.newBuilder()
.setName("processPayment")
.setDescription("Processes a payment using credit card details.")
.setParameters(Schema.newBuilder()
.setType(Type.OBJECT)
.putProperties("creditCardNumber", Schema.newBuilder().setType(Type.STRING).setDescription("The credit card number.").build())
.putProperties("expiryDate", Schema.newBuilder().setType(Type.STRING).setDescription("The expiry date of the card.").build())
.putProperties("cvv", Schema.newBuilder().setType(Type.STRING).setDescription("The CVV of the card.").build())
.putProperties("amount", Schema.newBuilder().setType(Type.NUMBER).setDescription("The amount to be paid.").build())
.addRequired("creditCardNumber")
.addRequired("expiryDate")
.addRequired("cvv")
.addRequired("amount")
.build())
.build();
}
// The resilient utility method to handle various input types from the LLM
public static String getStringFromObject(Optional<Object> obj) {
if (obj.isEmpty()) {
return "";
}
Object value = obj.get();
if (value instanceof String) {
return (String) value;
}
if (value instanceof Map) {
// If it's a map, try to find a "value" or "text" key, or just convert the whole map
Map<?, ?> map = (Map<?, ?>) value;
if (map.containsKey("value")) {
return String.valueOf(map.get("value"));
}
if (map.containsKey("text")) {
return String.valueOf(map.get("text"));
}
return map.toString();
}
if (value instanceof List) {
// If it's a list, return the first element or the whole list as a string
List<?> list = (List<?>) value;
if (!list.isEmpty()) {
return String.valueOf(list.get(0));
}
return "";
}
// For Numbers or any other type
return String.valueOf(value);
}
}
Designing for Reality, Not Idealized Schemas
Reliable AI agents are not built by assuming perfect model behavior—they are built by designing for
variability. The most common failures in agent-based systems occur at the boundary between natural
language
reasoning and deterministic tool execution. Treating tool inputs as untrusted, providing corrective
feedback, persisting critical state, and explicitly guiding execution flow are not optional
optimizations;
they are foundational requirements for production-grade agents.
The practices outlined in this article reflect a broader shift in how we should think about agent
design.
LLMs excel at interpretation and reasoning, but robust systems emerge only when that flexibility is
paired
with defensive engineering. By acknowledging and accommodating the inherent unpredictability of model
outputs, we can build agents that are not only intelligent, but dependable.
Now that you have understood the best practices for data extraction, are you interested in how to manage the tokens in Agents?
Imagine applying these concepts to manage the security of oAuth tokens in Agents for security best practices. Check out our guide on building enterprise grade applications with the On Behalf Of Token for Agents.