Taming Context Bloating: Optimizing LLM Memory with Google ADK
In the world of LLM agents, more context isn't just expensive—it's dangerous.As conversations evolve, the seamless accumulation of chat history, massive tool outputs, and latent metadata creates a critical failure state known as Context Bloating. This isn't merely a scaling tax; it is a systemic reliability risk that degrades reasoning, induces hallucinations, and eventually collapses the agent's logic.
To build production-grade agents, we must move beyond passive history storage. With the Google AI SDK (ADK), we implement Surgical Lifecycle Management—active, runtime interventions that keep models lean, precise, and operationally viable.
The Invisible Tax: $O(n^2)$ Complexity
Context bloating isn't linear. Most Transformer-based LLMs utilize self-attention mechanisms where the computational complexity (and memory requirement) grows quadratically with the sequence length.
KV Cache Exhaustion
Each token added requires memory in the Key-Value (KV) Cache. A bloated context causes memory pressure on the inference server, leading to pre-empted requests or massive latency spikes.
The $O(n^2)$ Attention Wall
Doubling your context doesn't just double your time; it can quadruple the attention computation, destroying your Time-to-First-Token (TTFT) metrics.
Case Study: Google Gemini AI Studio Max Context Error
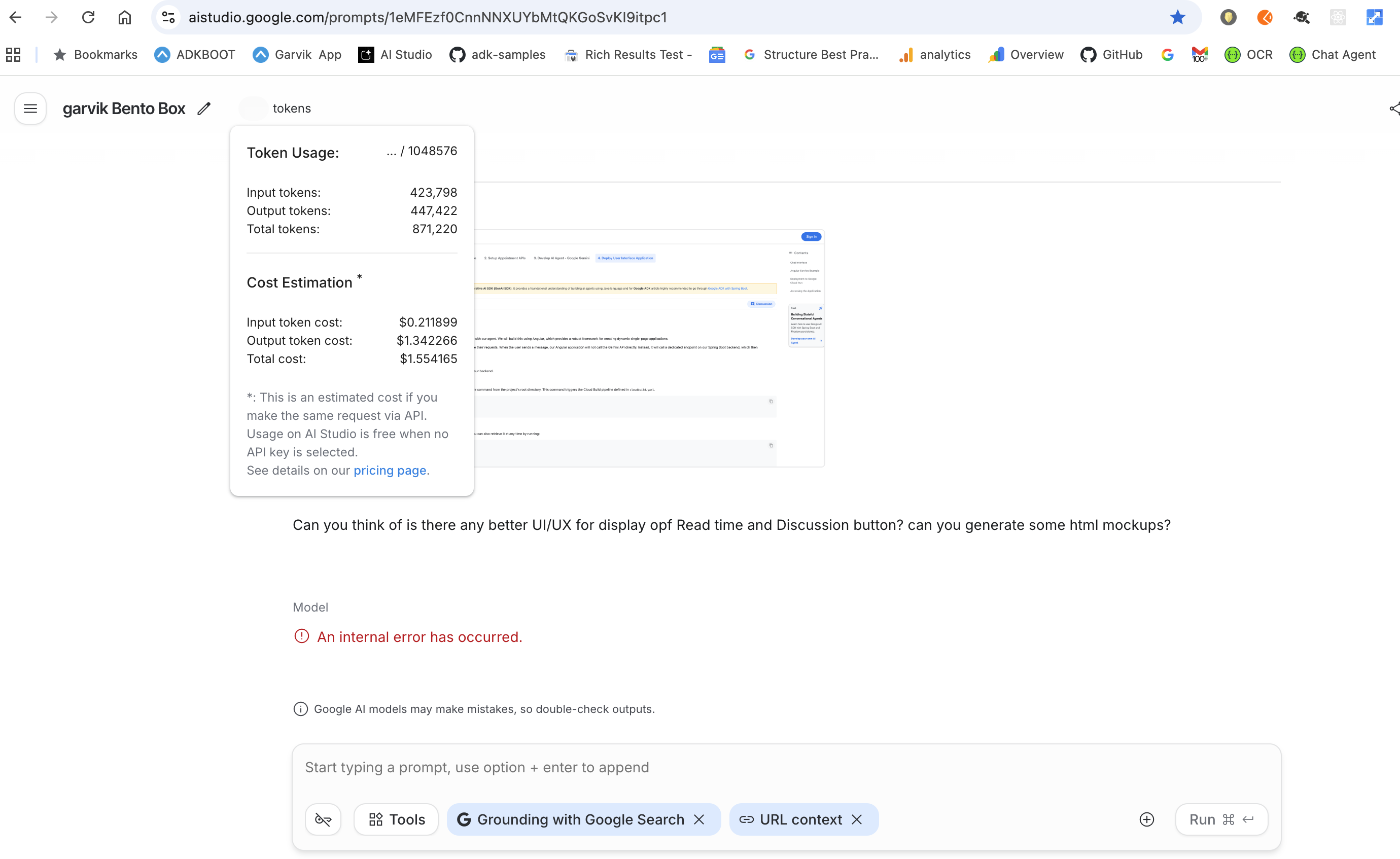
Anatomy of a "Max Context" Failure
The screenshot above from Google AI Studio captures a critical failure mode generic
Internal Error caused by hitting the computational ceiling of the model.
This highlights two concurrent forces that crash production agents:
-
1. Extremely High Token Usage
The session shows 423,798 input tokens. While the most of the model will have upper limit of some tokens , pushing context density this high creates immense pressure on the inference backend. The likelihood of a timeout or memory failure increases significantly when the context gets heavy like above 80% of the model's capacity. -
2. The "Thinking" Multiplier
Crucially, the Thinking Level is another factor that amplifies the impact of context bloating. Set to High. This forces the model to perform extensive internal Chain-of-Thought reasoning before outputting a single character.
The Fatal Equation:Massive Context (400k) × Deep Reasoning = Timeout. The request is likely timing out on Google's servers before the model can synthesize an answer from such a vast dataset.
Why this matters for Business:
In a business application, this isn't just an error—it's an SLA Breach.
You cannot build a business service that returns "Internal Error" when the problem gets hard.
Addressing context bloating isn't just about cost optimization; it is the only way to guarantee
system reliability and a generic error-free user experience.
The Hidden Cost of "Forward and Forget"
When an agent "resends" the entire history back and forth on every turn, it triggers a chain reaction of under-the-hood performance penalties:
Payload Bloom
As history grows, your request payload size explodes. Sending 100KB of JSON history every turn consumes ingress bandwidth, increases serialization time, and adds significant latency before the model even sees the prompt.
Prompt Prefill Latency
Before the model generates a single token, it must "digest" the entire input. This Prefill Stage is computationally heavy; for long contexts, the model spends seconds just parsing history, leading to a sluggish "frozen" UX.
KV Cache Hydration
Stateless API calls force the inference server to re-compute everything from scratch. Without smart context management or caching, you lose the benefits of keeping the model's KV cache "warm," resulting in slower per-token generation.
Anatomy of a Logic Collapse
Beyond performance, bloat causes Instruction Dilution—the phenomenon where the model's core system prompt loses its "gravitational pull" as it gets buried under thousands of tokens of noisy tool logs.
Lost in the Middle
Research confirms LLMs struggle to retrieve information buried in the middle of long contexts. Critical user intent becomes "invisible" to the agent.
Reasoning Decay
Large JSON tool outputs introduce "noisy features." The model begins to prioritize temporary data structures over its original logical objective.
Indirect Prompt Injection
A bloated context guarantees a larger attack surface. Malicious instructions retrieved by tools can "hijack" the session if not pruned immediately.
The Observability Black Hole
Debugging a 120k+ token session is operationally impossible. When context is bloated, finding the root cause of a hallucination becomes a needle in a digital haystack.
Surgical Intervention: ADK Lifecycle Hooks
The Google ADK provides powerful Lifecycle Callbacks that act as high-performance interception points. Instead of a "spray and pray" approach to context, we treat the prompt as an ephemeral workspace that must be cleaned at every turn.
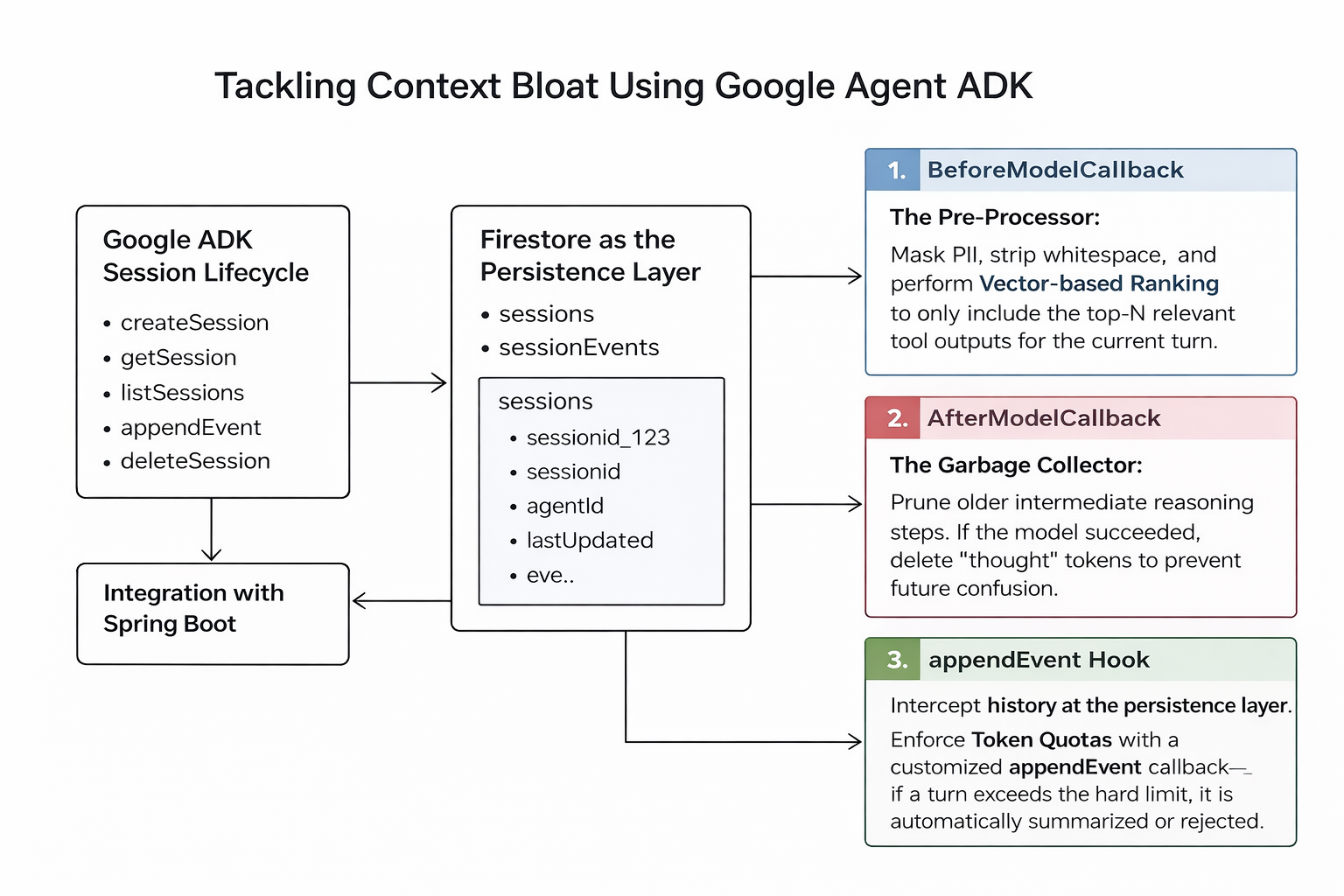
1. BeforeModelCallback
The Pre-Processor: Mask PII, strip whitespace, and perform Vector-based Ranking to only include the top-N relevant tool outputs for the current turn.
2. AfterModelCallback
The Garbage Collector: Prune older intermediate reasoning steps. If the model succeeded, delete the "thought" tokens to prevent future confusion.
3. appendEvent Hook
Intercept history at the persistence layer. By customizing the appendEvent callback, you can enforce Token
Quotas—if a Turn exceeds a hard limit, it is automatically summarized or rejected.
The "Three-Pillar" or "Trifecta" Architecture: Compliance Meets Efficiency
In production business applications, satisfying strict audit and compliance requirements while maintaining performant context management often requires a multi-layered approach. A highly effective strategy involves orchestrating three distinct lifecycle hooks to decouple compliance logging from context optimization.
1. The Compliance Layer (Before & After Callbacks)
Utilize BeforeModelCallback to capture raw user input immediately upon receipt.
This ensures the exact user intent is stored before any sanitization or truncation
occurs. Similarly, once the model generates a completion, capture the raw response and link
it permanently to the user's input in your data store. This guarantees a complete, verifiable
audit trail that satisfies regulatory compliance without polluting the active context window.
2. The Session Reconstruction Layer (appendEvent)
The appendEvent() hook remains responsible for building the immediate chat history
from the transactional data store. This ensures that the active session context remains
consistent and accurate for the ongoing conversation, serving as the "short-term memory" for the
agent.
3. The Optimization Layer (Async Context Compaction)
Instead of monitoring every transactional write (which is noisy and inefficient), we move token
usage calculation to the AfterModelCallback. Since this phase is purely
computational, we can check the current context density against a defined
threshold (e.g., 70%).
The Trigger Mechanism:
If the threshold is breached, we trigger an asynchronous cleanup event for that
specific conversation ID. This background process reads the full history from Firestore and
performs "smart compaction"—summarizing older turns or pruning low-value tokens. This offloads
expensive compaction logic from the critical path, ensuring user latency remains low while
keeping the context lean.
To implement these patterns in a production environment.
Explore our guide on Building Stateful Agents with Google AI SDK & Spring Boot.The "Smart Pruning" Pattern
A production-ready agent should evaluate its history after every turn. If the token count exceeds a threshold, it should prune or summarize.
public class ContextManager implements Callbacks.AfterModelCallback {
@Override
public Flowable<Event> run(TurnContext turnContext, Event event) {
Session session = turnContext.session();
List<Content> history = session.getHistory();
// 1. Check for context "pressure"
if (history.size() > 10) {
logger.info("Context pressure detected. Initiating sliding window...");
// 2. Keep System Instructions + User/Base turns
// but remove older intermediate tool-calls/responses
List<Content> prunedHistory = history.stream()
.filter(content -> !content.role().equals("TOOL_OUTPUT"))
.skip(Math.max(0, history.size() - 6))
.collect(Collectors.toList());
session.updateHistory(prunedHistory);
}
return Flowable.just(event);
}
}Advanced Strategies
Beyond sliding windows, consider these "Enterprise" patterns:
Semantic Summarization
Every 5 turns, ask a secondary LLM to summarize the key points of the conversation and replace those turns with a single "Memory" block.
Tool Caching
If a tool returns the same data (e.g., a huge policy doc), keep the reference (ID) in the context but remove the actual text until specifically requested again.
Role-Based Pruning
Prioritize keeping "USER" and "MODEL" turns while aggressive pruning "TOOL" outputs which are often verbose and transient.
Conclusion: Optimization is Not Optional
Managing context is not a "nice-to-have" optimization; it is the difference between a toy and a tool. An agent that remembers everything is eventually an agent that understands nothing.
By utilizing Google ADK lifecycle hooks to implement sliding windows, semantic summaries, and aggressive pruning, you transform your AI from a memory-hogging liability into a lean, production-ready enterprise asset.
Ready to scale?
Check out MCP Architecture guide to see
how to scale tools across distributed services.